Distributed Search Engine
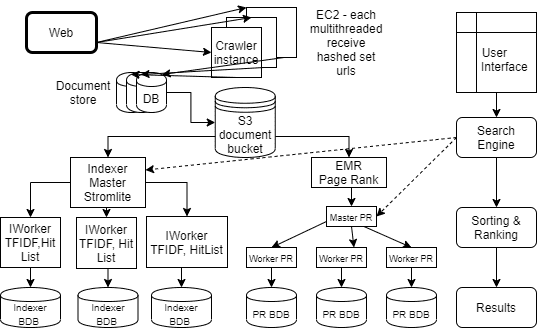
We designed and implemented a distributed search engine adopting Mercator style crawler to implement efficient crawling, used Stormlite framework for indexing, Apache Hadoop framework for PageRank and a clean, quick and high quality user interface for the search engine along with some interesting extra features.
University of Pennsylvania CIS555:Internet and Web systems Tools: AWS, Java, BerkeleyDB, Spark Java, Amazon S3, Amazon EC2, Apache Storm, Apache Hadoop Teammates: Shashank Prasad, Shruti Sinha, Garvit Khandelwal Project Report |
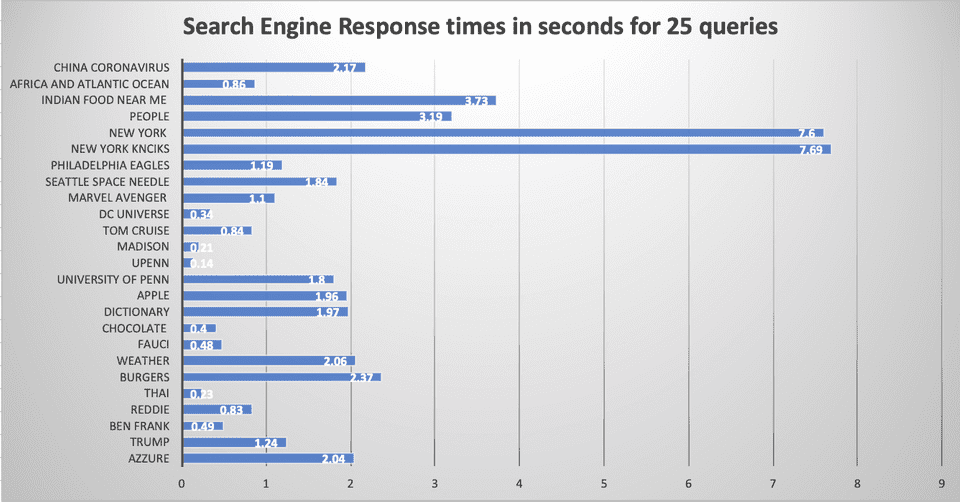
GRS2 is a distributed and scalable search engine built of a streaming framework called stormlite, which is a lightweight version of Apache Storm. We implemented an in-memory cache to keep track of commpon queries submitted by users which improved the search performance significantly. Integrated with additional APIs such as Yelp and Weather to improve the search experience. I was responsible for the web crawler which included:
|
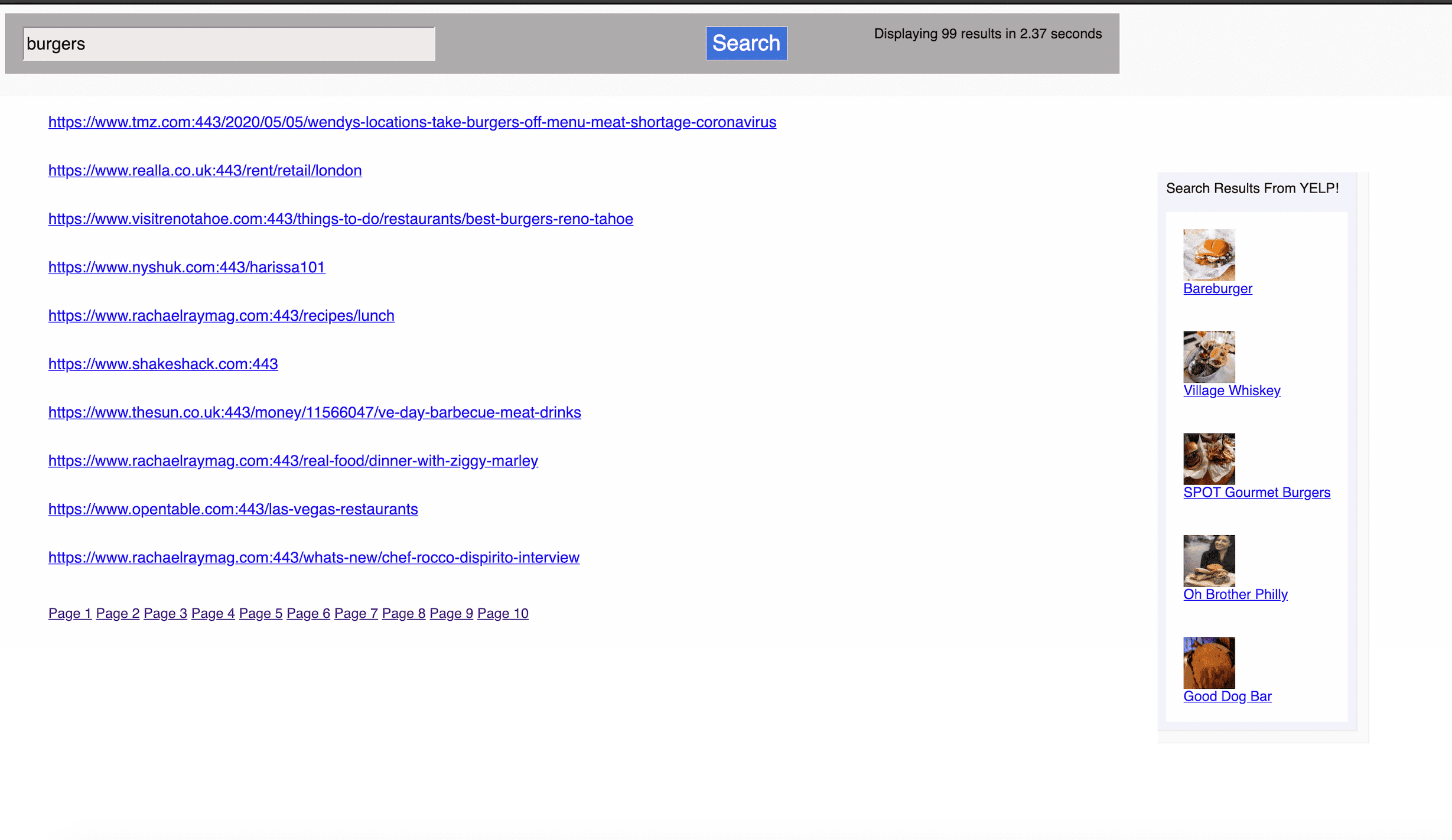 Screenshot of UI
Screenshot of UI
Published 1 Apr 2020